Future: Parallel & Distributed Processing in R for Everyone

University of California
A 20-minute presentation, eRum 2018, Budapest, 2018-05-16
R package: future 

- "Write once, run anywhere"
- A simple unified API ("interface of interfaces")
- 100% cross platform
- Easy to install (~0.4 MiB total)
- Very well tested, lots of CPU mileage, production ready
╔════════════════════════════════════════════════════════╗ ║ < Future API > ║ ║ ║ ║ future(), value(), %<-%, ... ║ ╠════════════════════════════════════════════════════════╣ ║ future ║ ╠════════════════════════════════╦═══════════╦═══════════╣ ║ parallel ║ globals ║ (listenv) ║ ╠══════════╦══════════╦══════════╬═══════════╬═══════════╝ ║ snow ║ Rmpi ║ nws ║ codetools ║ ╚══════════╩══════════╩══════════╩═══════════╝
High Performance Compute (HPC) clusters

Backend: future.batchtools 

- batchtools: Map-Reduce API for HPC schedulers,
e.g. LSF, OpenLava, SGE, Slurm, and TORQUE / PBS - future.batchtools: Future API on top of batchtools
╔═══════════════════════════════════════════════════╗
║ < Future API > ║
╠═══════════════════════════════════════════════════╣
║ future <-> future.batchtools ║
╠═════════════════════════╦═════════════════════════╣
║ parallel ║ batchtools ║
╚═════════════════════════╬═════════════════════════╣
║ SGE, Slurm, TORQUE, ... ║
╚═════════════════════════╝
Backend: future.batchtools
> library(future.batchtools)> plan(batchtools_sge)> a %<-% slow_sum(1:50)> b %<-% slow_sum(51:100)> a + b[1] 5050Building on top of Future API

Frontend: future.apply 

- Futurized version of base R's
lapply(),vapply(),replicate(), ... - ... on all future-compatible backends
╔═══════════════════════════════════════════════════════════╗ ║ future_lapply(), future_vapply(), future_replicate(), ... ║ ╠═══════════════════════════════════════════════════════════╣ ║ < Future API > ║ ╠═══════════════════════════════════════════════════════════╣ ║ "wherever" ║ ╚═══════════════════════════════════════════════════════════╝
aligned <- lapply(raw, DNAseq::align)Frontend: future.apply
- Futurized version of base R's
lapply(),vapply(),replicate(), ... - ... on all future-compatible backends
╔═══════════════════════════════════════════════════════════╗ ║ future_lapply(), future_vapply(), future_replicate(), ... ║ ╠═══════════════════════════════════════════════════════════╣ ║ < Future API > ║ ╠═══════════════════════════════════════════════════════════╣ ║ "wherever" ║ ╚═══════════════════════════════════════════════════════════╝
aligned <- future_lapply(raw, DNAseq::align)Frontend: future.apply
- Futurized version of base R's
lapply(),vapply(),replicate(), ... - ... on all future-compatible backends
╔═══════════════════════════════════════════════════════════╗ ║ future_lapply(), future_vapply(), future_replicate(), ... ║ ╠═══════════════════════════════════════════════════════════╣ ║ < Future API > ║ ╠═══════════════════════════════════════════════════════════╣ ║ "wherever" ║ ╚═══════════════════════════════════════════════════════════╝
aligned <- future_lapply(raw, DNAseq::align)plan(multiprocess)plan(cluster, workers = c("n1", "n2", "n3"))plan(batchtools_sge)
Frontend: doFuture 

- A foreach adapter on top of the Future API
- Foreach on all future-compatible backends
╔═══════════════════════════════════════════════════════╗
║ foreach API ║
╠════════════╦══════╦════════╦═══════╦══════════════════╣
║ doParallel ║ doMC ║ doSNOW ║ doMPI ║ doFuture ║
╠════════════╩══╦═══╩════════╬═══════╬══════════════════╣
║ parallel ║ snow ║ Rmpi ║ < Future API > ║
╚═══════════════╩════════════╩═══════╬══════════════════╣
║ "wherever" ║
╚══════════════════╝
doFuture::registerDoFuture()plan(batchtools_sge)aligned <- foreach(x = raw) %dopar% { DNAseq::align(x)}Frontend: drake - A Workflow Manager 
tasks <- drake_plan( raw_data = readxl::read_xlsx(file_in("raw-data.xlsx")), data = raw_data %>% mutate(Species = forcats::fct_inorder(Species)) %>% select(-X__1), hist = ggplot(data, aes(x = Petal.Width, fill = Species)) + geom_histogram(), fit = lm(Sepal.Width ~ Petal.Width + Species, data), rmarkdown::render(knitr_in("report.Rmd"), output_file = file_out("report.pdf")))future::plan("multiprocess")make(tasks, parallelism = "future")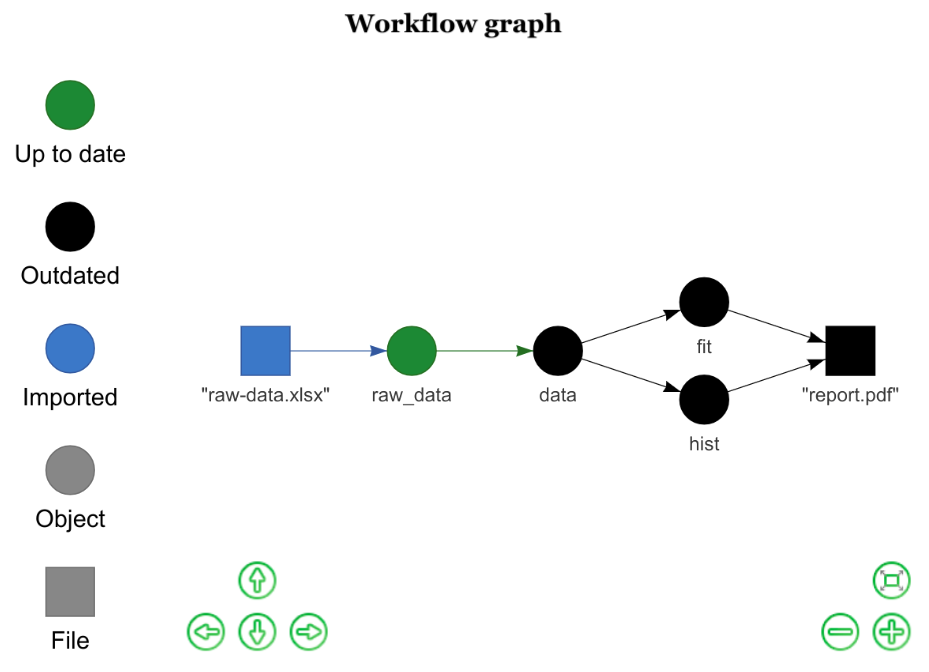
shiny - Now with Asynchronous UI 

library(shiny)future::plan("multiprocess")...Building a better future
bug reports,
and suggestions
 @HenrikBengtsson
@HenrikBengtsson HenrikBengtsson/future
HenrikBengtsson/future jottr.org
jottr.orgThank you!
A3.1 Plot remotely - display locally
> library(future)> plan(cluster, workers = "remote.org")## Plot remotely> g %<-% R.devices::capturePlot({ filled.contour(volcano, color.palette = terrain.colors) title("volcano data: filled contour map") })## Display locally> g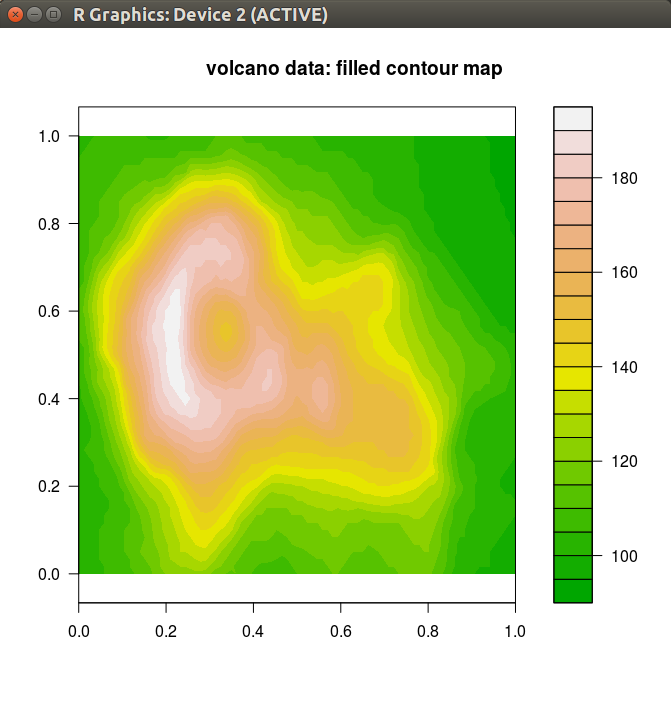
A3.2 Profile code remotely - display locally
> plan(cluster, workers = "remote.org")> dat <- data.frame(+ x = rnorm(50e3),+ y = rnorm(50e3)+ )## Profile remotely> p %<-% profvis::profvis({+ plot(x ~ y, data = dat)+ m <- lm(x ~ y, data = dat)+ abline(m, col = "red")+ })## Browse locally> p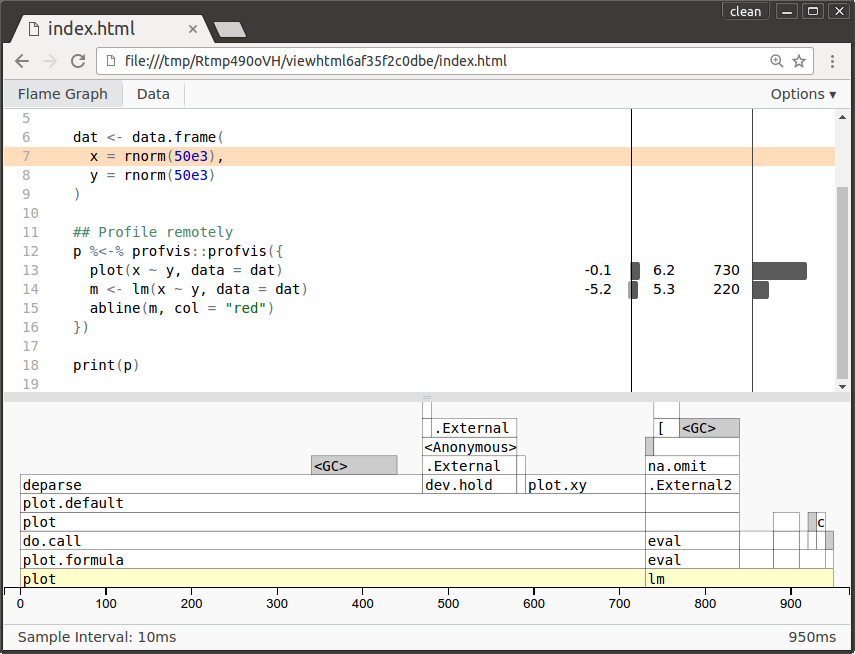
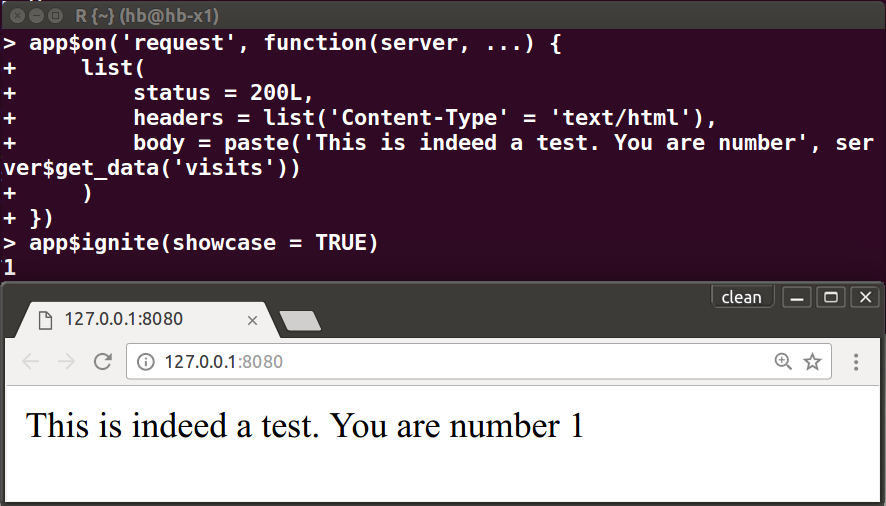
A3.3 fiery - flexible lightweight web server 
"... framework for building web servers in R. ... from serving static
content to full-blown dynamic web-apps"
A3.5 Backend: Google Cloud Engine Cluster
library(googleComputeEngineR)vms <- lapply(paste0("node", 1:10), FUN = gce_vm, template = "r-base")cl <- as.cluster(lapply(vms, FUN = gce_ssh_setup), docker_image = "henrikbengtsson/r-base-future")plan(cluster, workers = cl)A3.5 Backend: Google Cloud Engine Cluster
library(googleComputeEngineR)vms <- lapply(paste0("node", 1:10), FUN = gce_vm, template = "r-base")cl <- as.cluster(lapply(vms, FUN = gce_ssh_setup), docker_image = "henrikbengtsson/r-base-future")plan(cluster, workers = cl)data <- future_lapply(1:100, montecarlo_pi, B = 10e3)pi_hat <- Reduce(calculate_pi, data)print(pi_hat)## 3.1415